
Scenario
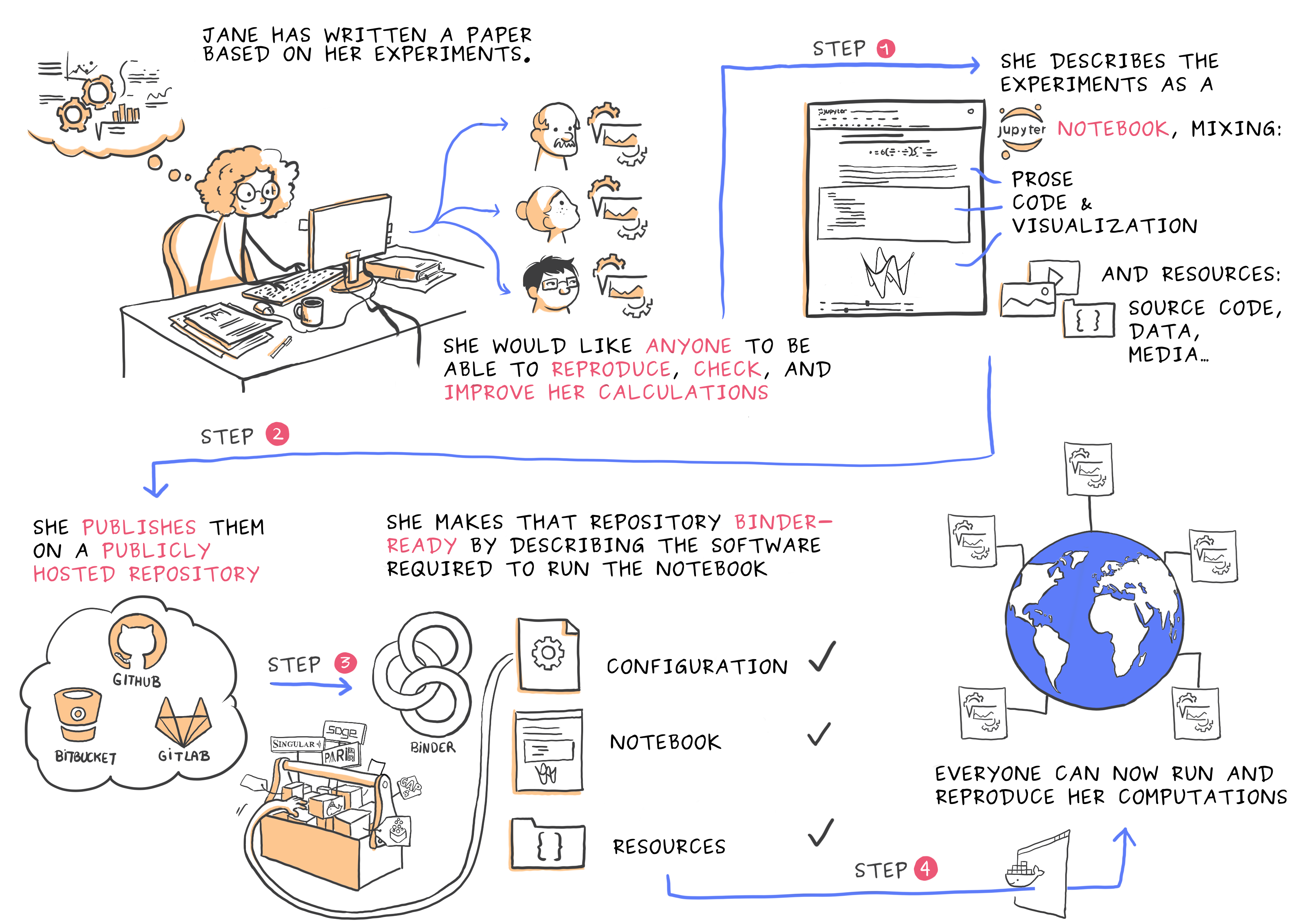
Jane has written a (math) paper based on her experiments. She would like anyone to be able to reproduce, check, and improve her calculations.
Suggestion of solution
-
She describes the experiments as Jupyter notebooks, mixing prose, code, visualization, together with resources: source code, data, media (think of them as logbooks);
-
She publishes them on a publicly hosted repository (e.g. on GitHub, …);
-
She makes that repository Binder-ready by describing the software required to run the notebooks; for details, see the Binder documentation, and check the configuration of the examples below.
Some instances
-
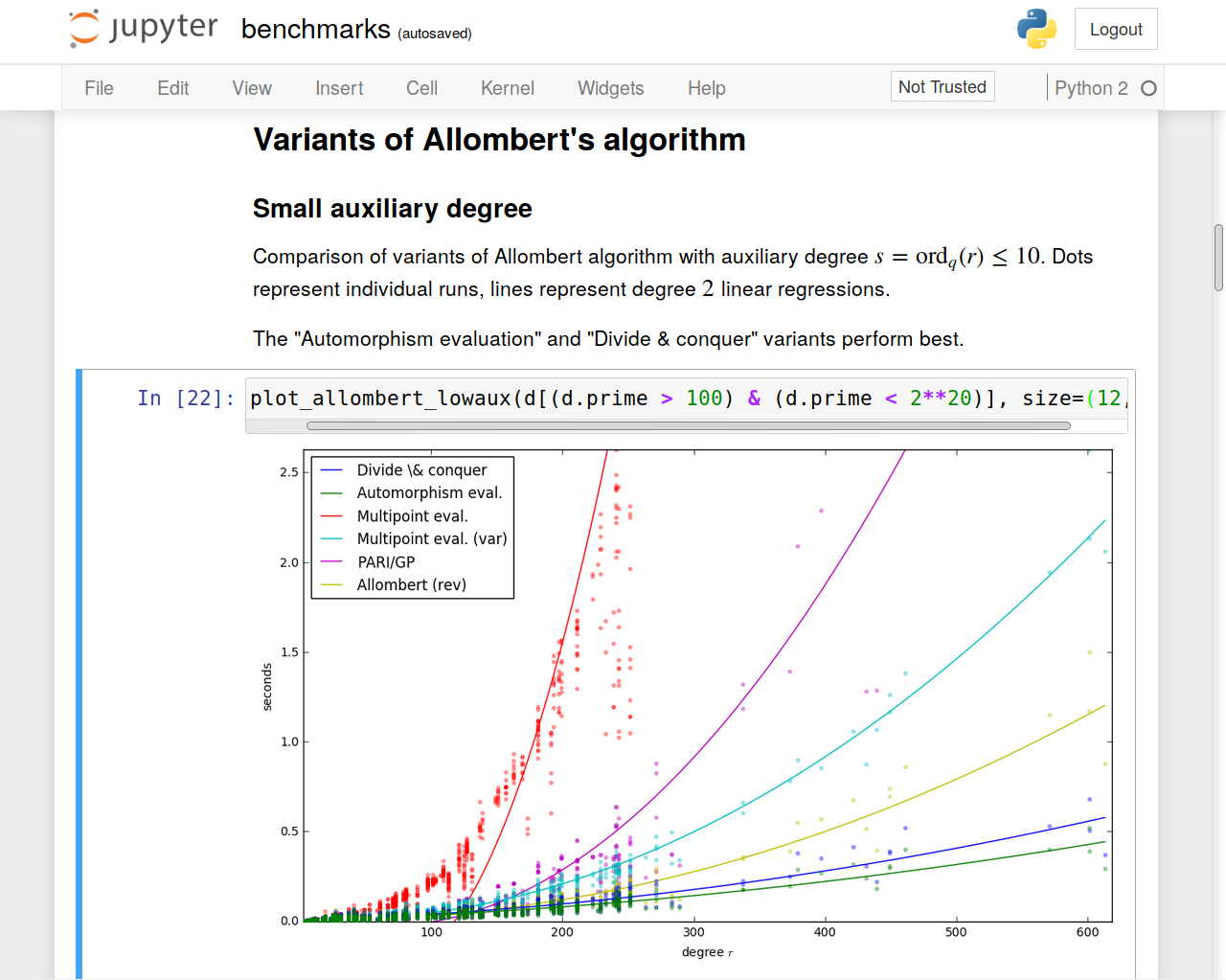
Computing isomorphisms and embeddings of finite fields, Ludovic Brieulle, Luca De Feo, Javad Doliskani, Jean-Pierre Flori and Éric Schost, arXiv:1705.01221 [cs.SC]

-
The 0-Rook monoid and its representation theory, Hivert and Gay
-
Estimating variances in time series linear regression models using empirical BLUPs and convex optimization, Martina Hančová, Gabriela Vozáriková, Andrej Gajdoš and Jozef Hanč, arXiv:1905.07771
Discussion
By publishing the log books and resources on a publicly hosted repository, Jane also guarantees their long term archival thanks to the Software Heritage project.
The proposed solution takes care of many of the basic hurdles for reproducibility, especially if following the recommended best practices (like pinpointing the versions of the dependencies). Full reproducibility however is intrinsically hard and many aspects are not tackled, like numerical instability, long term availability of software or long term backward compatibility of software and hardware. Also, only relatively lightweight calculations are covered. Nevertheless this hopefully covers the 20% of Pareto’s principle.
To do
- Estimate the number of such instances;
- Provide a template.
Time and expertise required
Assuming Jane is familiar with version control and Jupyter (basic lab skills taught at Software Carpentry, that the experiments were prepared as notebooks, and the software required is packaged (conda, debian, docker container, …), the publishing part could take two hours the first time, and half an hour later on.
What’s new since OpenDreamKit started
- Apparition of Binder;
- Expansion of the Jupyter technology;
- Better packaging and interfacing of math software.
OpenDreamKit contribution
- Development and contributions to Jupyter interfaces (kernels) for math software (GAP, Pari/GP, SageMath, Singular) and C++; see D.47.
- Contributions to the packaging of math software (GAP, Pari/GP, SageMath, Singular, …); see D3.1 and D3.10;
- Early adoption of Binder;
- Contributions to the deployment of new Binder instances;
- Advertising, training, providing a template (TODO!), …
Credits
- Illustration: Juliette Taka & Nicolas M. Thiéry. (2018).
Publishing reproducible logbooks explainer comic strip.
Zenodo. . CC-BY-SA.
</ul>
</small>
. CC-BY-SA.
</ul>
</small>
Front Page Jupyter Use Cases Open Science and Reproducibility Best Practice Reproducibility Binder