
Select by tag
All activities 224
Workshops and Conferences 132
Blog 34
SageMath 28
Front Page 28
Jupyter 25
Talks 24
WP6: Data/Knowledge/Software bases 21
Math-in-the-Middle 15
WP2: Dissemination 14
Job opening 14
Project Meetings 12
Use Cases 11
Open Science and Reproducibility 10
Release 9
GAP 8
Teaching 8
nbdime 7
Emerging Technologies 7
Best Practice 7
Pari/GP 6
Reproducibility 6
Pythran 5
Binder 5
WP4: User Interfaces 5
WP1: Management 5
WP5: HPC 5
Project reviews 5
Singular 4
Diversity 4
Cloud 4
H2020 4
Cython 3
OOMMF 3
LMFDB 3
Windows 3
Conference 3
CICM 3
Technical Blogpost 3
SageMathCloud 2
LinBox 2
Docker 2
MPIR 2
Publications 2
Future funding 2
WP3: Component Architecture 2
Sphinx 1
Sustainability 1
A key concept in science is that of reproducibility: Imagine a researcher or research group carries out a study, comes to a conclusion and publishes this. We call the work reproducible, if the publication describes the study in such way that another research group can follow the description, repeat the study and come to the same conclusion.
The issue of reproducibility is particularly acute when computer based work is involved, for example to generate data or analyse data. For full reproducibility, it is required to archive the software, to record exactly which processing steps where carried on which order on what data and how figures, tables and other results were obtained from that. Ideally, any software that is used should be open source so that there are no ‘hidden steps’ in processing.
Reproducibility raises a number of challenges, including a technical and social one.
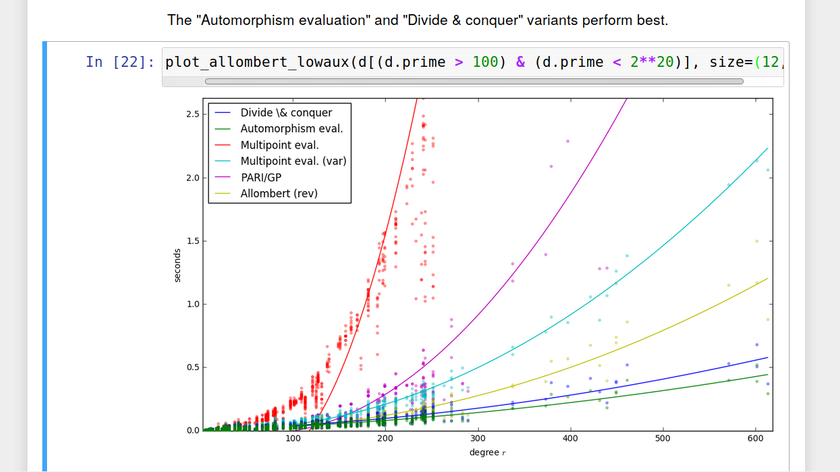
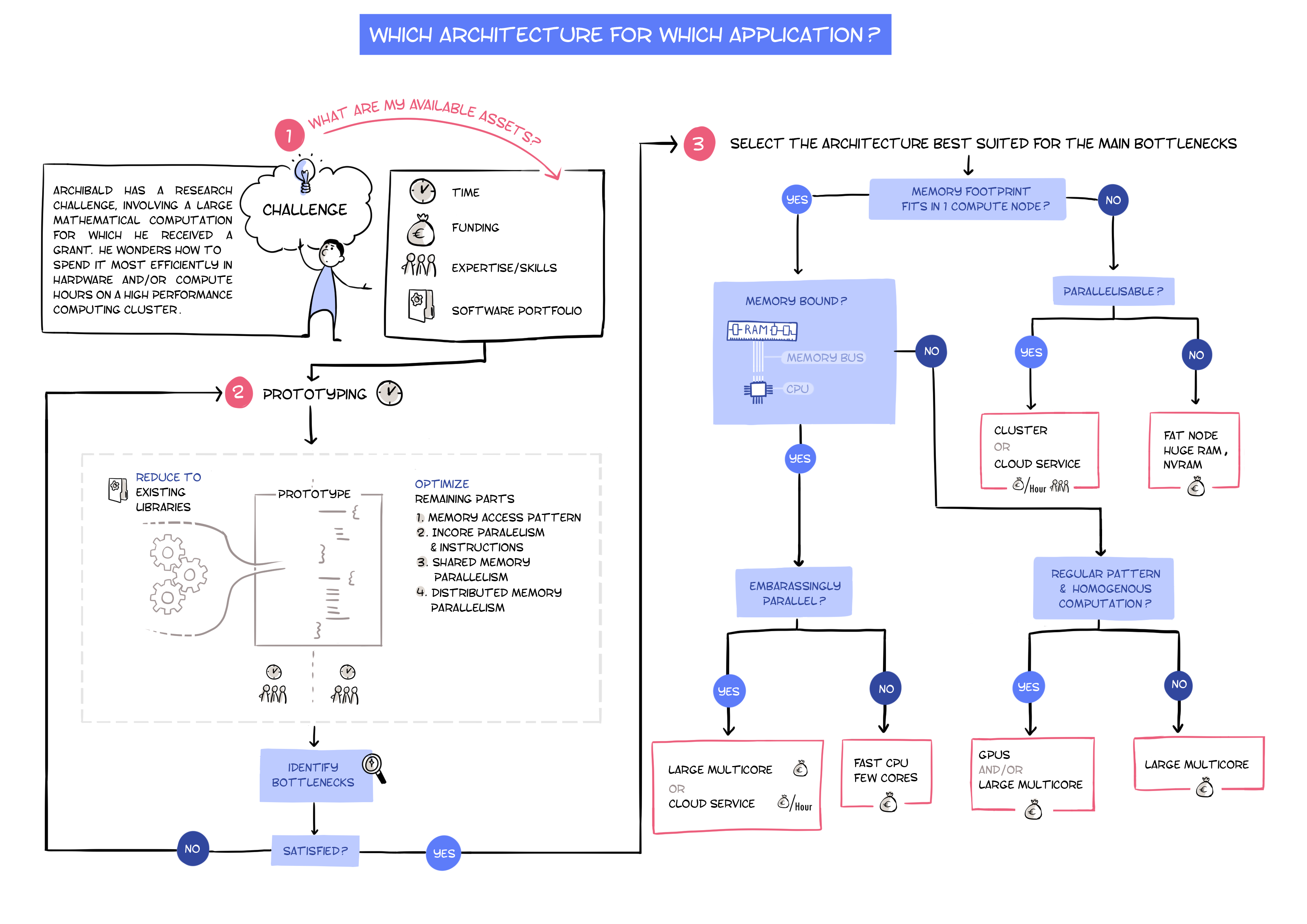
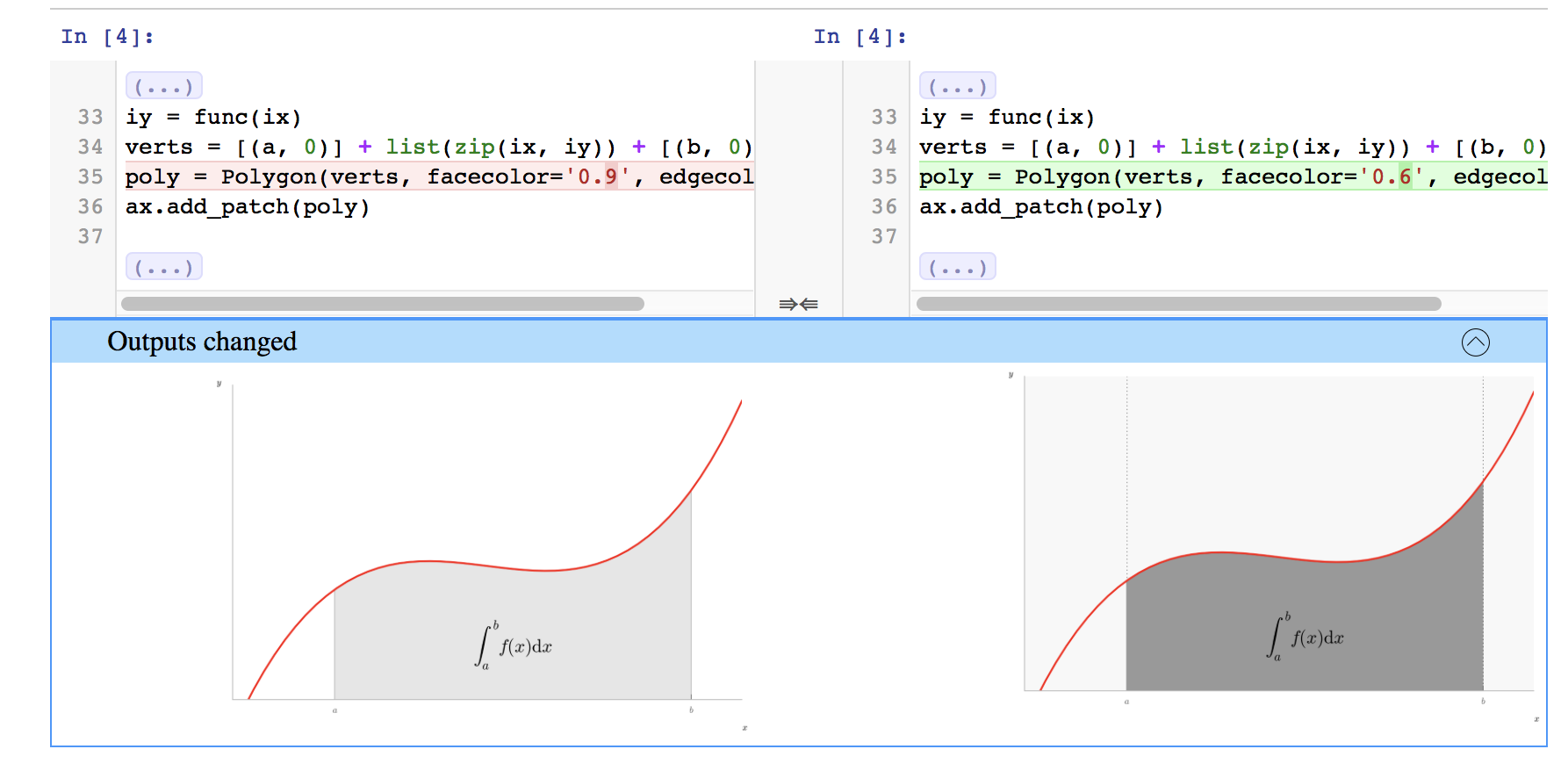
One the technical side, the OpenDreamKit project enables and improves more reproducible research by allowing to drive computational science inside the Jupyter Notebook, which provides a full and detailed record of computational steps taken, together with the results obtained. It also allows to annotate the results, thus capturing the key elements of a scientific study: experiment, processing and interpretation. This makes in easier for the scientists to log their actions, and share this with others - for example an as appendix to a publication. Further technical work includes the creation of the NBVAL package and support of the Binder project that archives the computational environment in which such a notebook can execute successfully.
On the social side, it is important to convince scientists, but more so journal editors and policy makers that reproducibility is important for better science and more effective use of taxpayers money. OpenDreamKit runs a wide range of workshops to spread this message and train scientists in use of the relevant tools.
Collaborating with Jupyter notebooks
Learn more >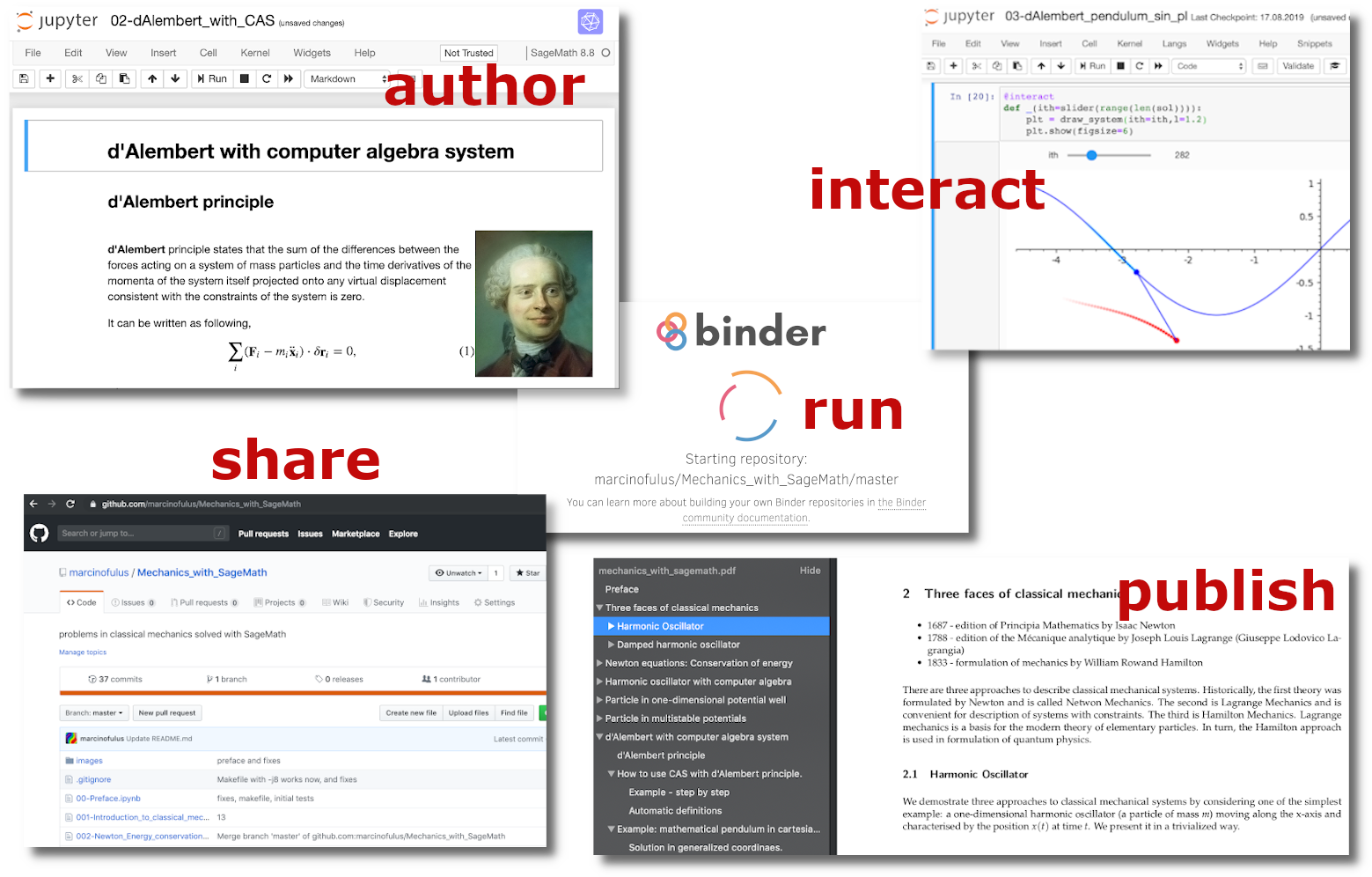
Authoring interactive books with Jupyter notebooks
Learn more >
Live online slides with SageMath, Jupyter notebooks, RISE and Binder
Learn more >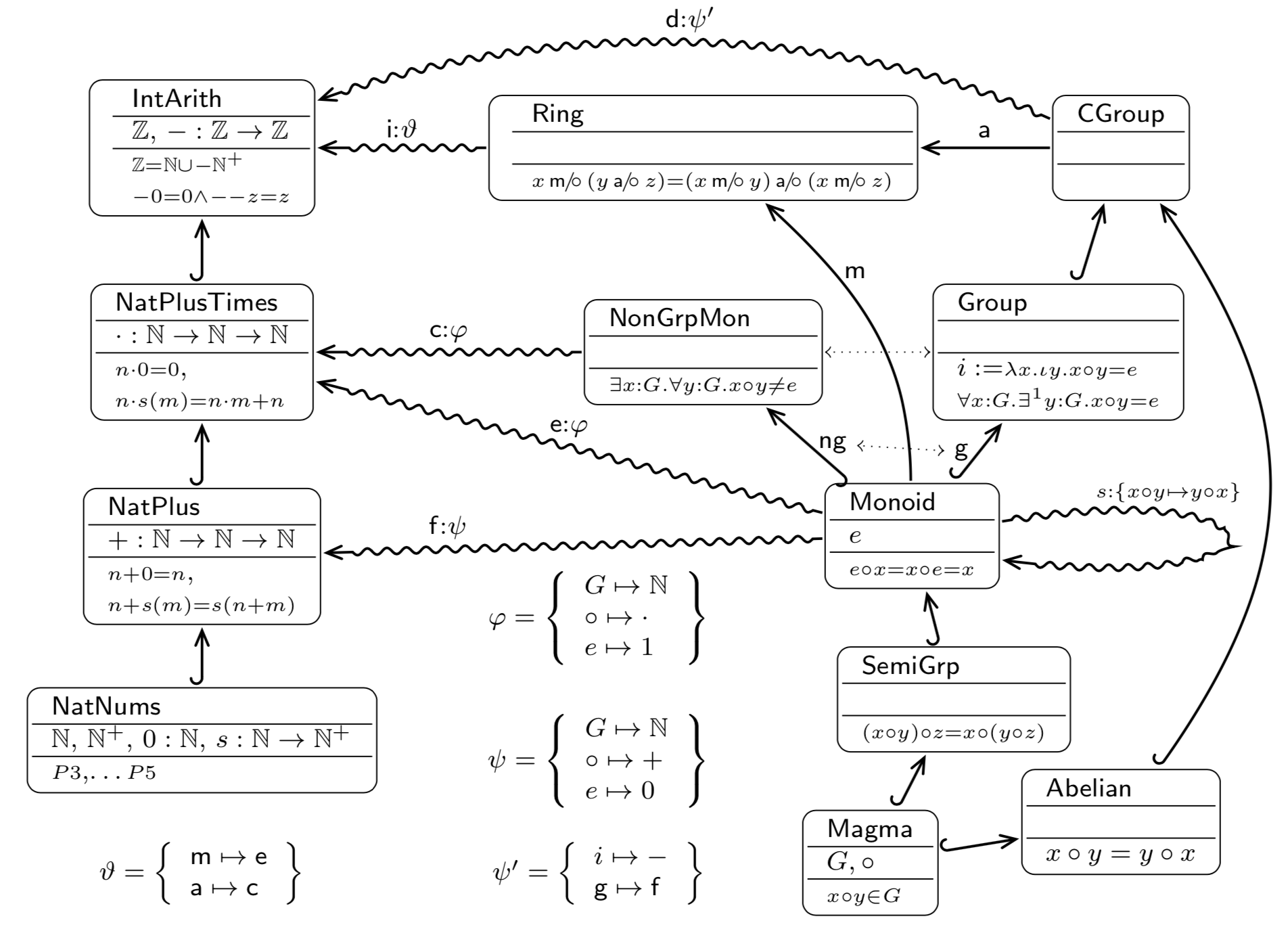
New OMDoc/MTT tutorial for mathematicians
Learn more >Leveraging literate computing technology for teaching: a template web site for jupyter-based courses
Learn more >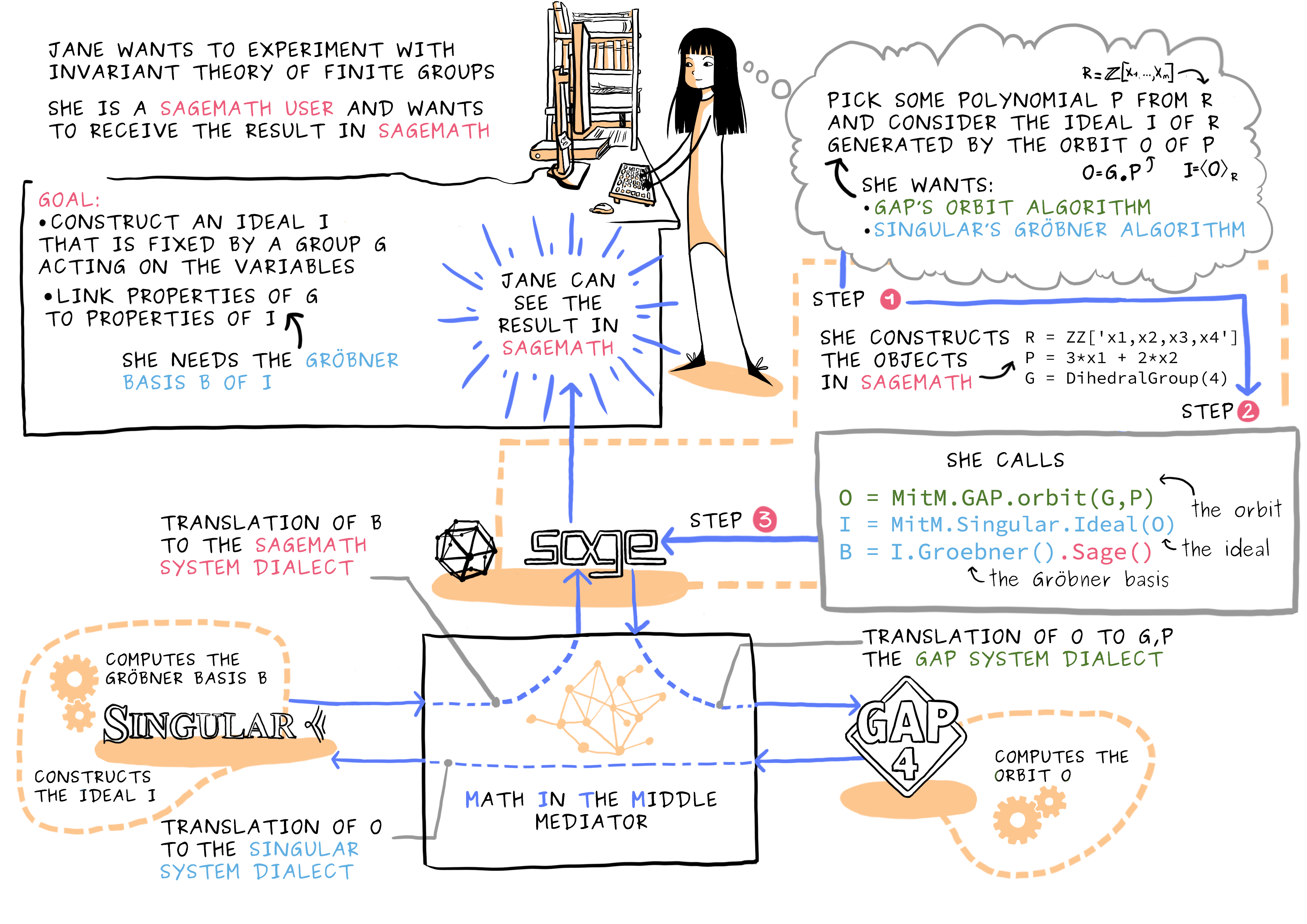
Composing mathematical computational software and databases: MitM to the rescue
Learn more >