
Scenario
Archibald has a challenge mathematical computation to run for which he received a grant. He wonders how to spend it most efficiently in hardware and/or compute hours on a high performance computing cluster.
Suggestion of solution
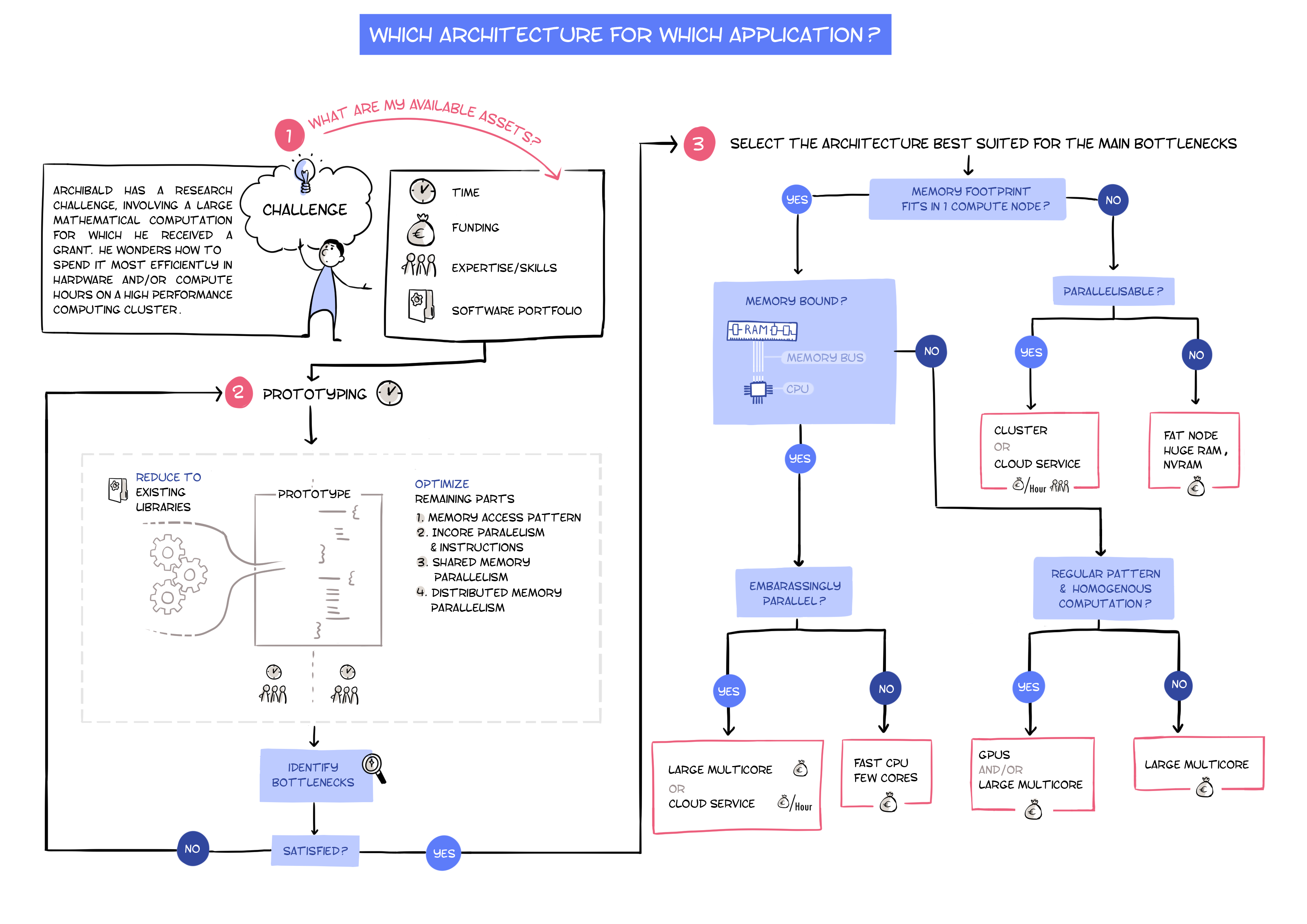
- He draws the resource consumption profile of his computation as precisely as possible:
- identifies the main computational bottlenecks
- then for each of them identifies:
- the overall memory footprint (memory space required by Input and Output, together with the allocations of intermediate computations)
- whether the computation is memory bound (about the same amount of computation as data) or compute bound (significantly more computation than data).
- the level of parallelism between tasks
- the regularity pattern of the computation.
-
Investigate ways (algorithmic, problem reformulation), if any, to make most of the computational effort rely on a regular, compute intensive, kernels.
- Select the architecture best suited bor the main bottlenecks among the following:
- High speed single core (or few-cores) machine.
- Large scale multi-core server
- high end GPU on a standard multi-core server
- hours on a large scale distributed cluster of heterogeneous servers (academia)
- hours on a large scale high end homogeneous distributed cluster depending on the type of computations:
| Fast single core | Large scale multi-core | High-end GPU | Heterogeneous cluster | Uniform cluster | |
|---|---|---|---|---|---|
| Compute intensive | ✓ | ✓ | ✓ | ||
| Regularity (SIMD) | ✓ | ||||
| Memory intensive | ✓ | ✓ | |||
| Large data (near 1Tb) | ✓ | ||||
| Huge data (several Tb) | ✓ | ✓ | |||
| Embarassingly parallel | ✓ | ✓ | ✓ |
Design of high performance code for mathematical computing
Before throwing any effort in code developpment, Archibald tries to make use of any specialised library providing high performance implementations for some kernels he is focusing on.
Overall the design of new code solving the problem should focus on optimizing the following points incrementally.
- optimizing the memory access patterns: cache optimization
- optimizing the use of in-core parallelism: using SIMD instructions, arithmetic units, etc
- shared memory parallelization:
- applied from the coarsest to the finest grain
- optimizing data placement and memory allocation (numactl, tcmalloc, etc)
- technology choice:
- pthreads: full control, often too low level w.r.t. application
- OpenMP: good level of abstraction, now take advantage of task based dependency DAGs. Still struggles with recursive tasks and large task queues
- Cilk, XKaapi, SMPSS, star-PU: more powerfull, but risk of discontinued support
- Message passing based distributed computing (MPI):
- tune the serialization layer
- use hybrid MPI-OpenMP: exploiting shared memory within nodes.
Front Page Use Cases Open Science and Reproducibility Best Practice